Blog
2038 Problem: Building Better Tools for Boring Infrastructure Work
How SZNS and AI Agents can help solve the year 2038 problem
John (feat. Vint Cerf)
Oct 30, 2025
Yesterday at the 2025 Google Cloud Public Sector Summit, I had the pleasure of catching up with Dr. Cerf. As usual, our discussions/debates around Bitcoin began and he started challenging me with security concerns for Bitcoin with regard to quantum (a post on that for another day). Anyway, the conversation ended up going to the 2038 problem and he said I should write a blog post about it. And when Vint Cerf tells you to write a blog post about something, you write one.

Got my DGX sparks signed 😀 (but very sad Jensen could not attend, was hoping I’d get lucky)
What breaks in 2038
I don’t think the “2140 problem” with Bitcoin is actually going to be a problem when mining rewards end around that time, but the 2038 Problem is real. On January 19, 2038 at 03:14:07 UTC, many systems may have a bad time. Unix timestamps store time as a 32-bit signed integer counting seconds since January 1, 1970, giving you about 2.1 billion seconds before the counter wraps around and suddenly thinks it's December 13, 1901.
Our phones will probably be fine since most modern systems switched to 64-bit timestamps. But embedded systems, legacy databases, financial software, IoT devices, and about a million other things running on 32-bit architectures will need to be fixed. The financial sector is particularly exposed with mortgage contracts, insurance policies, pension calculations – anything with dates past 2038 is already touching this bug.
Y2K was actually fixed
Y2K panic is now remembered fondly(?). Media hysteria about planes falling from the sky, nuclear reactors melting down, banking systems collapsing. What gets forgotten is that none of that happened because engineers actually fixed the problem.
The media narrative was apocalyptic while the engineering reality was methodical and boring. Teams audited codebases, updated date fields, tested patches, and deployed fixes. It cost money (estimated to be around $300 billion globally), took years, and mostly worked because people started early enough.
By the way, the hysteria had an interesting, useful side effect: it got budget approved. CTOs could point to cable news and get funding for infrastructure upgrades that should have been happening anyway. Fear can be a decent forcing function.
What actually worked for Y2K was starting early (mid-90s for many organizations) with systematic auditing of codebases and databases with lots of testing and incremental fixes.
Dr. Cerf’s point is that we should start the same early work now, for good reasons below.
Why 2038 is different
Y2K was mostly a software problem: change some date formats, update some logic, ship some patches. The 2038 problem cuts deeper because hardware also gets involved.
You can't just patch an embedded system that's been running in a factory control system for 15 years. That PLC doesn't get updates. It barely gets looked at. Same goes for IoT devices, automotive systems, medical equipment, and industrial controllers.
The other issue is surface area. In 1999, we had fewer systems, they were more centralized, and they were easier to audit. Today we have billions of devices, most running embedded Linux, many with terrible update mechanisms or none at all. The supply chain complexity makes systematic fixes harder. And unlike Y2K, there's no clean date boundary. Financial systems are already dealing with dates past 2038. The bug is already active for any forward-looking calculations, less of a countdown to a single moment.
The core challenge isn't fixing individual systems. We know how to do that: migrate to 64-bit timestamps, update time_t definitions, recompile. The challenge is finding everything that needs fixing.
Large codebases accumulate dependencies like dust. That module you're using for date parsing calls a library. That library shells out to a system command. That command reads a config file. Somewhere in that chain, a 32-bit assumption lurks.
Auditing this manually is tough work. Exhaustive, repetitive, requiring attention to detail across thousands of files. We miss things. We get bored. We assume the last team handled it.
Plugging in SZNS & Agents
I have to do my job here and sell SZNS. This is exactly the kind of problem that LLM-based agents are getting good at, and the SZNS team are experts at developing and deploying these types of agents.
The agent can read through an entire codebase, understand the data flow, identify every place that touches time representations, trace dependencies, and flag potential issues. It can do this for millions of lines of code without getting tired or missing obvious patterns.
More importantly, it can propose fixes and validate them against test suites. The workflow looks something like:
The agent scans the codebase and identifies all timestamp usage. It traces data flow to see where 32-bit assumptions propagate. It checks database schemas, API contracts, serialization formats. It flags dependencies that need updating. Then it proposes changes, such as migrating time_t to 64-bit types, updating struct definitions, modifying serialization logic.
You review the changes, the agent runs tests, you iterate. The agent catches the cases you'd miss on manual review because it doesn't get mentally fatigued on the 847th occurrence of timestamp parsing.
The value isn't in replacing engineers. It's in replacing as much of the boring or painful work with agents so that aggregate productivity increases, rather than saving time. A team of five people using agents can audit what would have taken 50 people doing it manually. That changes the economics enough that organizations might actually do the work.
This is exactly the kind of problem we built SZNS Springboard to solve: production-grade ADK agents that can systematically audit codebases, integrate with your existing systems, and actually ship fixes rather than just generating reports. We've been deploying these kinds of agents in enterprise environments for a while now. If you’re interested in how we do this, contact us at partner@szns.solutions
Boring work matters
The 2038 problem isn't sexy. No one gets promoted for preventing infrastructure failures that don't happen, but this is the kind of work that distinguishes good engineering organizations from mediocre ones. The willingness to do systematic, unglamorous maintenance work. The discipline to fix things before they break rather than after.
If you want to start on this problem now, let’s work together. Many thanks to Dr. Cerf for the nudge to write this and for being an incredible human from the 24th century to save humanity.
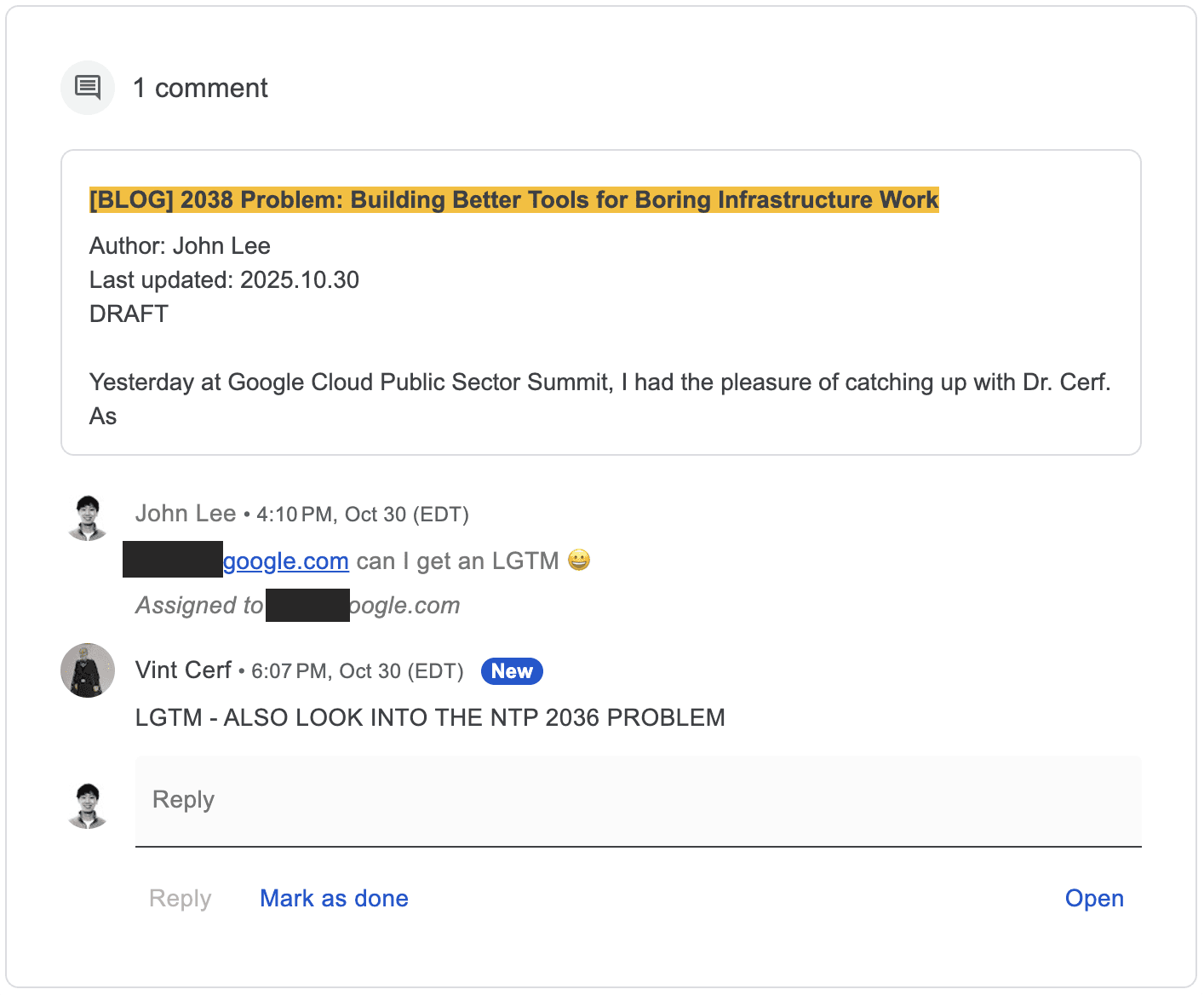
Looks like our next post will be on the NTP 2036 overflow, but I think that will be posted in our Engineering Blog with thoughts around why it will be better or worse than the Year 2038 problem. Stay tuned.